If there is one thing cumbersome in doing deep learning - apart from fiddling around with hyper parameters - it is to actually get the data to train on in the first place. You can download some excellent training datasets from Kaggle, but if you want to solve your own tasks you’ll have to build your very own image dataset.

Luckily transfer learning drastically reduces the required number of images for most classification problems, but you still have to come up with 100s to 1000s of images and (depending on the accuracy you’re after and the number of classes you require) this can be challenging.
Recently I struggled with this problem myself and after consulting the xkcd time vs. effort chart I created the python package fastclass to make the process less painful.
FastClass
You can get the script by simply installing from my GitHub like so:
pip install git+https://github.com/cwerner/fastclass.git#egg=fastclass
This will install two script in your $PATH: fastclass download (fcd) to pull images from various sites in the web, and fastclass clean (fcc) that is used to visually inspect the often messy results from such internet crawling.
Step 1: FastClass download
To download image categories from the net you first need to create a query csv file. The package comes with on example that should be located in the install location (your site-packages/fastclass folder).
head -n 3 example/guitars.csv
searchterm,exclude
guitar gibson les paul,guitar
guitar gibson SG,guitar
In the example, 25 different search terms are listed (column searchterm). In addition you specify exclusion terms. These are keywords you need for a successful search but don’t want to use as class labels (search and exclusion terms are separated with whitespace).
You start the download from the command line:
> fcd -c ALL -k -o guitars example/guitars.csv
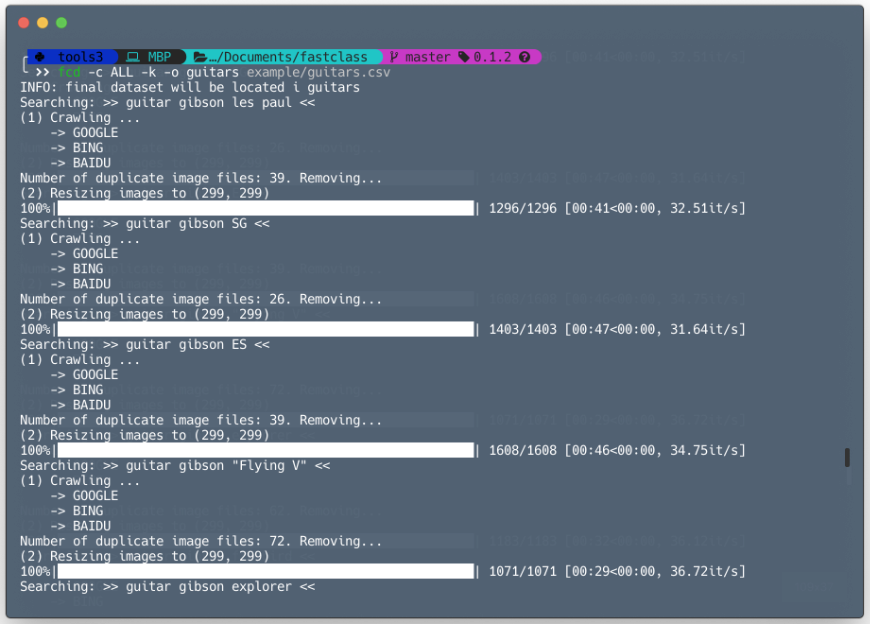
This will use all three search crawlers (Google, Bing, and Baidu), resize any image it downloads to the default size (299x299px) but also keep the originals, and store the files in the folder ‘guitars’. For details just use the help flag (‘-h’).
When the script is finished you will find subfolders for each row of your query csv file in the specified dataset folder. Furthermore, a log file containing the source URL for each image is reported. The source URL is also embedded as an EXIF tag:UserComment in the resized images. Duplicated images are detected and removed automatically.
Step 2: FastClass clean
Once the images are located on your drive you can inspect them quickly for the tool fcc. Call it by pointing to the category subfolder you want to inspect:
> fcc guitars/gibson_les_paul
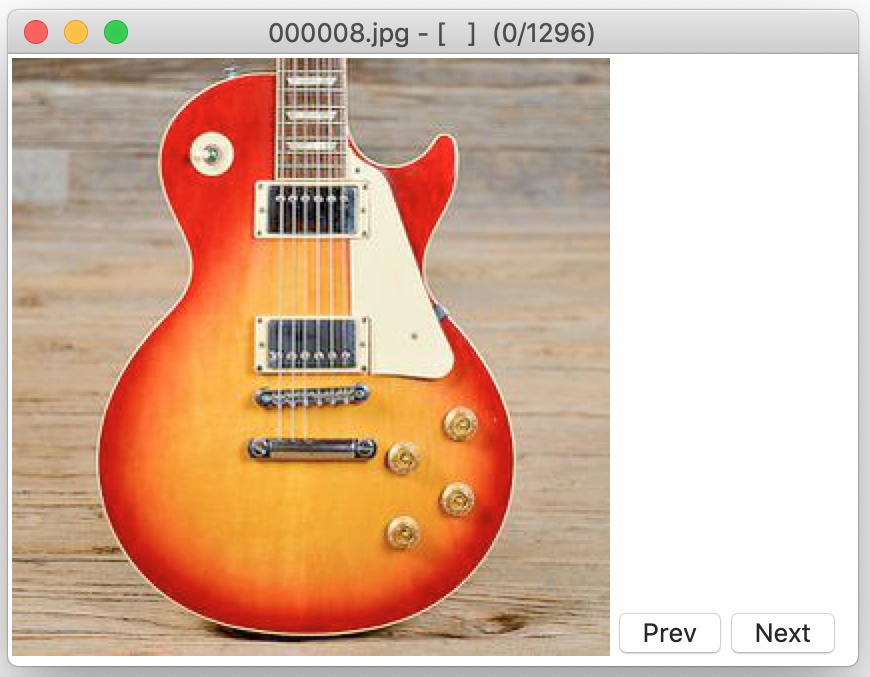
This will quickly launch a GUI with the first image. Use the arrow keys to navigate. To rate the file or choose a class by pressing the keys [1] to [9]. With [d] you can mark it for deletion and with [x] you terminate the script. Afterwards you will find a copy of the files that were not marked for exclusion and a report file with your ratings.
In future updates I want to improve the interface and possibly store the image information in a database to reduce clutter. I hope it is useful to you and in case of any issues please create an issue at https://github.com/cwerner/fastclass/issues or sent me a pull request.